Bonjour")
?Y a til un spécialiste pour interpréter mes données Scrutiny?
Copier/coller du dashbord :
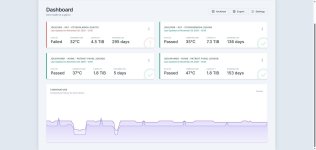
Dashboard
Drive health at a glance
/dev/sda - sat - ST5000LM000-2AN170
Last Updated on November 29, 2025 - 12:50
Status
Failed
Temperature
32°C
Capacity
4.5 TiB
Powered On
295 days
/dev/sdb - sat - ST8000DM004-2U9188
Last Updated on November 29, 2025 - 12:50
Status
Passed
Temperature
35°C
Capacity
7.3 TiB
Powered On
136 days
/dev/nvme1 - nvme - Patriot P400L 2000GB
Last Updated on November 29, 2025 - 12:50
Status
Passed
Temperature
37°C
Capacity
1.8 TiB
Powered On
5 days
/dev/nvme0 - nvme - Patriot P400L 2000GB
Last Updated on November 29, 2025 - 12:50
Status
Passed
Temperature
47°C
Capacity
1.8 TiB
Powered On
153 days
Temperature
Temperature history for each device
======
ma CC (docker‑compose.yml) ,bien configurée, atteste que Scrutiny voie bien mes 4 disques :
-le RAID1 formé par les 2 nvme,
-les 2 autres HDDs en mode BASIC
Je vois bien les 4 périphériques physiques dans le dashboard :
/dev/sda (HDD 5 To) → état Failed (je sais : le HD SEAGATE BarraCuda (ST5000LM000) a un problème! non détecté lors du test SMART complet par le tool UGOS!
-le test SMART de Scrutiny indique que le BarraCuda est en bon état, mais a un problème à : le Command Timeout (ID 188) a une valeur élevé de 4295032833 et a échoué! Les autres valeurs sont bonnes, sans secteurs réalloués ni erreurs graves. Le test approfondi avec loutil maison UGOS n'a pas détecté de secteurs défectueux et indique simplement Normal
/dev/sdb (HDD 8 To) → état Passed
/dev/nvme0 (NVMe 2 To, RAID1) → état Passed
/dev/nvme1 (NVMe 2 To, RAID1) → état Passed
Cela confirme que ta CC actuelle expose correctement les devices (sda, sdb, nvme0n1, nvme1n1). Scrutiny ne montre pas RAID1 comme une entité, mais les disques physiques qui le composent.
J'en conclue que : l'app surveille bien leur état de santé SMART.
?Pourquoi je ne vois plus les courbes de température?
-jusque à présent : les graphes apparaissaient puisque l'agent Scrutiny collectait plusieurs points de données,
-de mémoire juste après l’install de mai dernier, 1 seule valeur instantanée s'affichait mais pas de ligne graphique,
-après 6MOIS de collecte automatique (par défaut toutes les heures), les courbes devraient se voir dans le dash non?
-cela envoie mes données SMART au serveur influxDB et commence à remplir l’historique.
?Comment forcer une collecte immédiate avec : docker exec -it scrutiny scrutiny-collector-metrics run (j'ai lu cette commande? mais n'ose pas toucher à la CC qui semble fonctionner correctement)
Ma foi je ne comprends pas ce disfonctionnement?

?Y a til un spécialiste pour interpréter mes données Scrutiny?
Copier/coller du dashbord :
Dashboard
Drive health at a glance
/dev/sda - sat - ST5000LM000-2AN170
Last Updated on November 29, 2025 - 12:50
Status
Failed
Temperature
32°C
Capacity
4.5 TiB
Powered On
295 days
/dev/sdb - sat - ST8000DM004-2U9188
Last Updated on November 29, 2025 - 12:50
Status
Passed
Temperature
35°C
Capacity
7.3 TiB
Powered On
136 days
/dev/nvme1 - nvme - Patriot P400L 2000GB
Last Updated on November 29, 2025 - 12:50
Status
Passed
Temperature
37°C
Capacity
1.8 TiB
Powered On
5 days
/dev/nvme0 - nvme - Patriot P400L 2000GB
Last Updated on November 29, 2025 - 12:50
Status
Passed
Temperature
47°C
Capacity
1.8 TiB
Powered On
153 days
Temperature
Temperature history for each device
======
ma CC (docker‑compose.yml) ,bien configurée, atteste que Scrutiny voie bien mes 4 disques :
-le RAID1 formé par les 2 nvme,
-les 2 autres HDDs en mode BASIC
Je vois bien les 4 périphériques physiques dans le dashboard :
/dev/sda (HDD 5 To) → état Failed (je sais : le HD SEAGATE BarraCuda (ST5000LM000) a un problème! non détecté lors du test SMART complet par le tool UGOS!
-le test SMART de Scrutiny indique que le BarraCuda est en bon état, mais a un problème à : le Command Timeout (ID 188) a une valeur élevé de 4295032833 et a échoué! Les autres valeurs sont bonnes, sans secteurs réalloués ni erreurs graves. Le test approfondi avec loutil maison UGOS n'a pas détecté de secteurs défectueux et indique simplement Normal
/dev/sdb (HDD 8 To) → état Passed
/dev/nvme0 (NVMe 2 To, RAID1) → état Passed
/dev/nvme1 (NVMe 2 To, RAID1) → état Passed
Cela confirme que ta CC actuelle expose correctement les devices (sda, sdb, nvme0n1, nvme1n1). Scrutiny ne montre pas RAID1 comme une entité, mais les disques physiques qui le composent.
J'en conclue que : l'app surveille bien leur état de santé SMART.
?Pourquoi je ne vois plus les courbes de température?
-jusque à présent : les graphes apparaissaient puisque l'agent Scrutiny collectait plusieurs points de données,
-de mémoire juste après l’install de mai dernier, 1 seule valeur instantanée s'affichait mais pas de ligne graphique,
-après 6MOIS de collecte automatique (par défaut toutes les heures), les courbes devraient se voir dans le dash non?
-cela envoie mes données SMART au serveur influxDB et commence à remplir l’historique.
?Comment forcer une collecte immédiate avec : docker exec -it scrutiny scrutiny-collector-metrics run (j'ai lu cette commande? mais n'ose pas toucher à la CC qui semble fonctionner correctement)
Ma foi je ne comprends pas ce disfonctionnement?
Pièces jointes
Dernière édition: